




Кластеризация базы: как использовать доступные данные для эффективной группировки клиентов
Динамичеcкая модель кластеризации поможет определить приоритетные сегменты клиентов и их характеристики, оптимизировать маркетинг на их удержание и развитие, и понять факторы влияния на поведение.
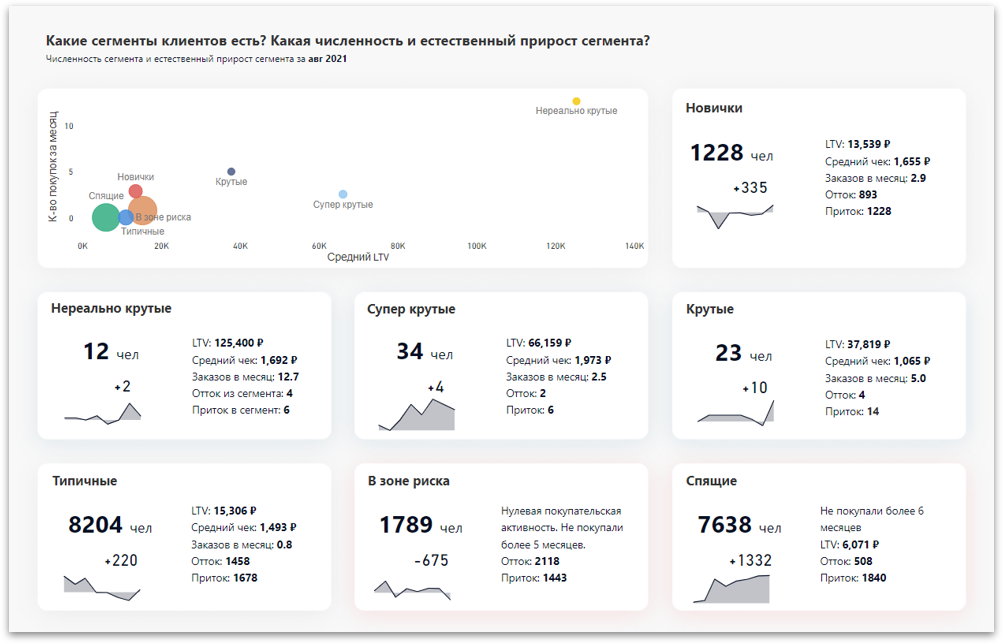
Компании-лидеры своих индустрий уже активно используют данный подход для принятия стратегических и операционных маркетинговых решений.











Кластеризация (англ. cluster analysis) - задача группировки множества объектов на подмножества (кластеры) таким образом, чтобы объекты из одного кластера были более похожи друг на друга, чем на объекты из других кластеров по какому-либо критерию.
Для руководителей, маркетологов, предпринимателей знание данного показателя крайне привлекательно, так как решает сразу несколько стратегических задач:
- высвобождает рекламные ресурсы (пока CAC*<LTV против CAC<CPO) в борьбе за долю рынка,
- увеличивает привлекательность компании для инвесторов,
- осмысленно персонализирует маркетинг.
“
Долгосрочный рост - вот ультимативная суть современного маркетинга, в котором основное внимание уделяется превращению разовых покупателей в постоянных лояльных клиентов.
Кластеризация в ручном режиме может быть выполнена с помощью Miro и некоторой интуиции. В примере ниже была база была разбита на 6 групп и 16 подгрупп исходя из размера покупок клиентов, объема накопленных ими бонусов.

А также для подтверждения найденных гипотез разделения может быть проведен анализ зависимости дохода с клиентов, как в примере выше, от баланса баллов и уровня их накопления.

было выяснено, что..
Кластеризация как метод полного анализа базы клиентов
Сегментация базы по признакам однородности позволяет сгруппировать клиентов в крайне похожие друг на друга группы используя все доступные события, которые человек совершал (например, жалобы, использование мобильных приложений, просмотр контента, стратегии использование баллов итд), транзакционные данные (купленная коллекция, размер скидки, время/день покупки итд).
Обычно для сегментации используются стандартные модели RF/RFM или ее аналоги. Однако они сложны для качественной интерпретации и мало-информативны как следствие.
Мы рекомендуем использовать кластеризацию как более надежный подход, учитывающий всё знание компании о клиентах. Пример разработки модели кластеризации . С такой моделью разделения клиентов на группы компания сможет через BI решение регулярно оценивать:
Таким образом у компании значительно улучшается способность выделять приоритетные группы, оценивать изменения их метрик, сопоставляя с действиями компании как в области ПЛ, так и на всем разнообразии 4P факторов.
Обычно для сегментации используются стандартные модели RF/RFM или ее аналоги. Однако они сложны для качественной интерпретации и мало-информативны как следствие.
Мы рекомендуем использовать кластеризацию как более надежный подход, учитывающий всё знание компании о клиентах. Пример разработки модели кластеризации . С такой моделью разделения клиентов на группы компания сможет через BI решение регулярно оценивать:
- Сколько клиентов совершает "качественные" переходы (те повышают свою ценность) или наоборот меняют сегмент на менее ценный;
- Корреляцию переходов между сегментами и влияние на LTV/выручку;
- Описать сегменты в целевых метриках и сравнивать их с прошлым периодом;
- Составить популярные пути клиентов по сегментам и их разнообразие.
Таким образом у компании значительно улучшается способность выделять приоритетные группы, оценивать изменения их метрик, сопоставляя с действиями компании как в области ПЛ, так и на всем разнообразии 4P факторов.

Визуализация кластеров (сегментов)
Задача
Понимать основные характеристики кластеров и как меняется их численность
Решение
Карточки кластеров с естественным приростом и основными характеристиками
Метрики
Численность кластера, естественный прирост кластера, LTV, AOV
Понимать основные характеристики кластеров и как меняется их численность
Решение
Карточки кластеров с естественным приростом и основными характеристиками
Метрики
Численность кластера, естественный прирост кластера, LTV, AOV
Аналитика кластеров
Задача
Оценивать в общих чертах влияние на повышение лояльности
Решение
Группировка перетоков клиентов между кластерами на:
- Повысили уровень (если новый кластер клиента лучше, чем предыдущий)
- Понизили уровень
- Без изменений
Метрики
Количество и доля клиентов, которые стали более / менее лояльными.
Оценивать в общих чертах влияние на повышение лояльности
Решение
Группировка перетоков клиентов между кластерами на:
- Повысили уровень (если новый кластер клиента лучше, чем предыдущий)
- Понизили уровень
- Без изменений
Метрики
Количество и доля клиентов, которые стали более / менее лояльными.


Перетоки в сегментах
Задача
Оценивать тенденции в изменении поведения клиентов и влияние изменений на средний LTV
Решение
Визуализация перетоков клиентов между кластерами и сравнение среднего LTV до/после перехода в сегмент
Метрики
Количество клиентов, осуществивших переток; средний LTV
Оценивать тенденции в изменении поведения клиентов и влияние изменений на средний LTV
Решение
Визуализация перетоков клиентов между кластерами и сравнение среднего LTV до/после перехода в сегмент
Метрики
Количество клиентов, осуществивших переток; средний LTV
Оценка типовых путей клиентов и их кол-ва
Необходимо для оценки основных траекторий в которых "живут" клиенты до ухода (отток) или перехода в более ценные группы
Зная их, компания может вести их оптимальным образом.
Зная их, компания может вести их оптимальным образом.


Оценка влияния перетоков на бизнес метрики
Задача
Понимать как изменение в поведении клиентов влияет на выручку / суммарный LTV. Какие факторы сдерживают рост?
Решение
Расчет суммарного прироста LTV по всем, кто совершил ту или иную смену кластера
Метрики
Отклонение LTV (прирост), LTV в прошлом месяце (до смены кластера), LTV текущий месяц (после смены кластера)
Понимать как изменение в поведении клиентов влияет на выручку / суммарный LTV. Какие факторы сдерживают рост?
Решение
Расчет суммарного прироста LTV по всем, кто совершил ту или иную смену кластера
Метрики
Отклонение LTV (прирост), LTV в прошлом месяце (до смены кластера), LTV текущий месяц (после смены кластера)
Скачать исследование
«Развитие и применение методологии LTV в странах России и СНГ»
«Развитие и применение методологии LTV в странах России и СНГ»

Кейс создания модели кластеризации
По нашему опыту, меньше 30% компаний считают LTV. И даже те кто делают редко удовлетворены текущим результатом по нескольким причинам:
- не интегрированы ключевые типы пользовательских данных в единую БД для старта работ
- компании сложно подобрать методику расчета, так как нет универсального подхода к подсчету LTV (разберем подробнее далее)
- при формальном получении LTV по простым формулам, например через churn rate (показатель оттока, пример ниже), остаются не определены факторы непосредственного влияния на метрику
- аналогично, метрика остается общей для компании, без возможности ее определения на определенные когорты (например, покупатели определенного месяца) или сегменты (как соц-дем группы, так и более узкие, например, покупатели с определенным товаром в первой покупке, или акционные )
- расчетный показатель не интегрирован в маркетинговые инструменты компании, или в противном случае - не изучается в полной мере на уровне HADI циклов
- нет системного внутреннего обсуждения какие образом компания может улучшить свои результаты
- переход от одной модели расчета к другой по мере подключения новых данных чреват значительным изменениями результата, что блокирует дальнейшее его исследование
Цель ₋ выявление скрытых сегментов клиентов и свойственных им закономерностей поведения.
Для достижения выбранной цели поставлены следующие задачи:
1. Определение пространства признаков кластеризации.
2. Проведение кластерного анализа.
3. Интерпретация полученных результатов.
Для достижения выбранной цели поставлены следующие задачи:
1. Определение пространства признаков кластеризации.
2. Проведение кластерного анализа.
3. Интерпретация полученных результатов.
Существующая модель сегментации клиентов на стороне заказчика имеет следующую структуру.
Основным недостатком существующей модели является жёсткая привязка к числу дней от даты последнего заказа без учёта всего имеющегося набора признаков, в связи с чем не представляется возможным адекватно оценивать складывающуюся ситуацию.
Основным недостатком существующей модели является жёсткая привязка к числу дней от даты последнего заказа без учёта всего имеющегося набора признаков, в связи с чем не представляется возможным адекватно оценивать складывающуюся ситуацию.
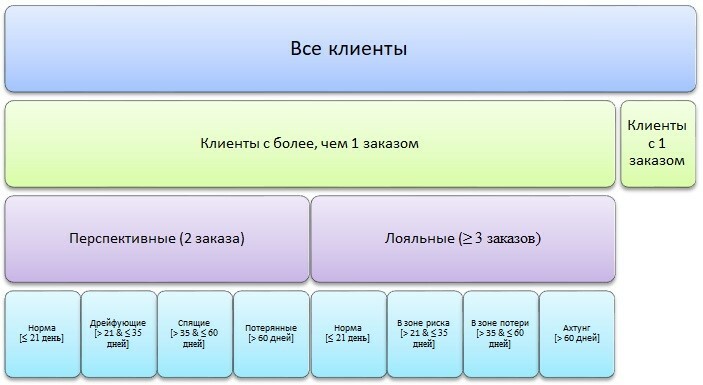
Как видно из новой схемы сегментации посредством проведенного анализа удалось выделить 8 характерных паттернов поведения клиентов, аккумулирующих в себе широкий спектр признаков, что впоследствии позволит более эффективно выстраивать с ними целевое взаимодействие.
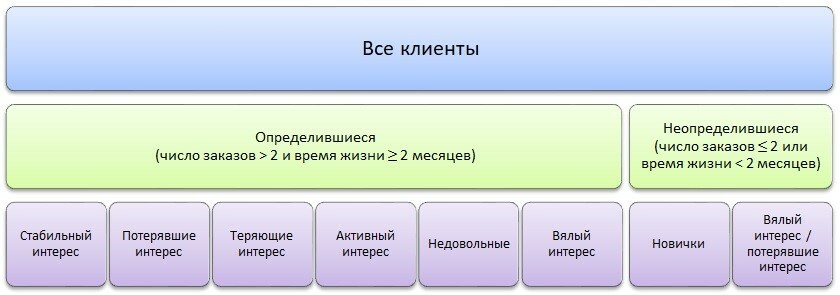
Подробнее работу с сегментами можно рассмотреть в видео.
Методология
В качестве метода кластеризации обычно используется метод k-средних, разбивающий оптимальным образом имеющееся число наблюдений на k непересекающихся классов.
Параметр k изначально неизвестен, что требует перебора вариантов его значений. Основными критериями выбора значения параметра k является его близость к точке перегиба на графике «каменистая осыпь» и интерпретируемость кластеризации.
Параметр k изначально неизвестен, что требует перебора вариантов его значений. Основными критериями выбора значения параметра k является его близость к точке перегиба на графике «каменистая осыпь» и интерпретируемость кластеризации.
- Обучение модели. Первый год истории покупок будет использоваться для определения факторов влияния, тогда как второй - для оценки фактического LTV этих клиентов
- Внедрение модели. В это же время, второй год истории - это данные для прогноза LTV по всем клиентам, которые еще не "прожили" с компанией полный год.
Для выделения паттернов поведения клиентов использовался временной период в течение 2 месяцев, выбранный исходя из задачи фиксировать паттерны поведения, характеризующиеся редкими, но регулярными покупками. Характеристика пространства признаков представлена в таблице 1.

Также было сформировано дополнительное пространство признаков, не участвующее в кластеризации, но служащее для представления дополнительной полезной информации о выделенных сегментах, дополнительное пространство признаков представлено в таблице 2.

Суммируя, весь процесс работы можно представить в следующие этапы, работа над которыми может продолжаться по мере подключения в проект новых данных, проведения экспериментов, а также улучшения качества модели за счет объема и качества данных.
“
Вместо того, чтобы думать о том, как можно привлечь много клиентов как можно дешевле, LTV помогает вам подумать о том, как оптимизировать ваши затраты на привлечение с максимальным ростом ценности базы, а не с минимальными затратами.
И для общего понимания потенциальных выгод расчета и использования LTV в алгоритмических подходах, а также их потенциальных сложностей внедрения рекомендуем ознакомиться с выступлением на Forum.Digital
Агрегирование разносторонних данных в единой БД
Создание модели данных (витрина) с перебором атрибутов
Модель классификации (churn) возврата клиента
Построение модели регрессии по целевой переменной
Улучшение качества модели за счет исключения факторов
1
2
3
4
5


Для запуска такого внутреннего решения, компания может использовать существующую BI инфраструктуру или построить модель на базе Power BI.
Развитие и применение практик в России и СНГ в 2022—2024
Исследование в области маркетинговой аналитики
Исследование в области маркетинговой аналитики

Пример BI отчета по кластеризации
В данном дашборде в Power BI построены отчеты для анализа оборачиваемости, АВС, ROI запасов и упущенной прибыли.
Для запуска такого внутреннего решения, компания может использовать существующую BI инфраструктуру или построить модель на базе Power BI.
Выгоды построения BI панелей с метрикой LTV:
- Позволяет оценить эффективность затрат при сравнении средних на пользователя (CPO) и дохода (LTV)
- Позволяет оценивать эффективность по сравнению с прошлым, так как LTV возможно рассчитать и для прошлого периода
- Позволяет выявить факторы влияния на оборот: управляемые и неуправляемые
- Оценить как изменение управляемых факторов влияет на будущий доход
Заявка на консультацию
Проконсультируем за чашечкой кофе
Ищете решение
сложной задачи на доступных данных?
сложной задачи на доступных данных?

Нажимая кнопку "Отправить заявку" вы принимаете политику обработки персональных данных сайта

© 2025 Coffee Analytics
Связаться с нами

Заказать услугу кластеризации (модель)
Нажимая на кнопку "Отправить" вы соглашаетесь с политикой обработки персональных данных
Получить исследование «Развитие и применение методологии LTV в странах России и СНГ в 2021-2022 гг»
Заполните форму, чтобы первыми получить доступ к презентации.
Нажимая на кнопку "Отправить" вы соглашаетесь с политикой обработки персональных данных
Получить исследование «Развитие и применение методологии LTV в странах России и СНГ в 2021-2022 гг»
Заполните форму, чтобы первыми получить доступ к презентации.
Нажимая на кнопку "Отправить" вы соглашаетесь с политикой обработки персональных данных
Получить подборку кейсов по кластеризации базы
Все нужные маркетологу материалы про методы разделения базы по признакам клиентов
Нажимая на кнопку "Отправить" вы соглашаетесь с политикой обработки персональных данных
Получить полную версию исследования методологии LTV в СНГ
Нажимая на кнопку "Отправить" вы соглашаетесь с политикой обработки персональных данных
Связаться с нами
Проконсультируем за чашечкой кофе.
Нажимая на кнопку "Отправить" вы соглашаетесь сполитикой обработки персональных данных